|
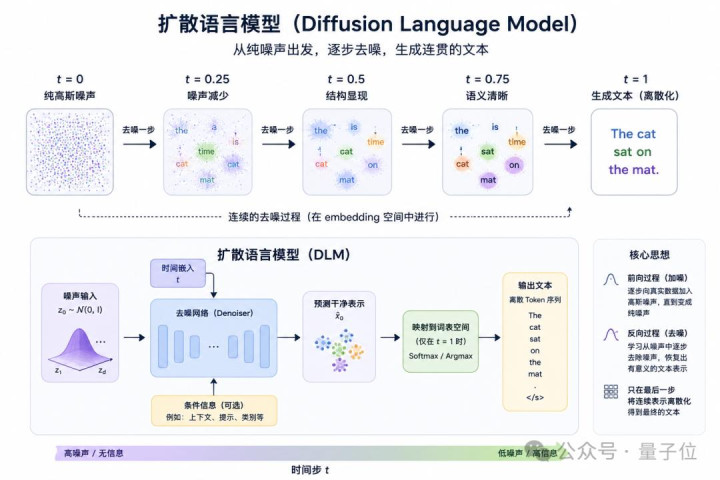
henry 发自 凹非寺 何恺明,也下场作念说话模子了。 只不外,此次他带队作念的不是寰球老练的、像ChatGPT背后那套“臆度下一个词元”(next token prediction)的自转头范式。 而是另一条当年几年在图像界限大火、如今正被越来越多东说念主搬进文本生成的新道路:扩散说话模子(Diffusion Language Model,DLM)。 在最新的论文中,何恺明团队放出全新运动扩散说话模子:ELF:Embedded Language Flows。
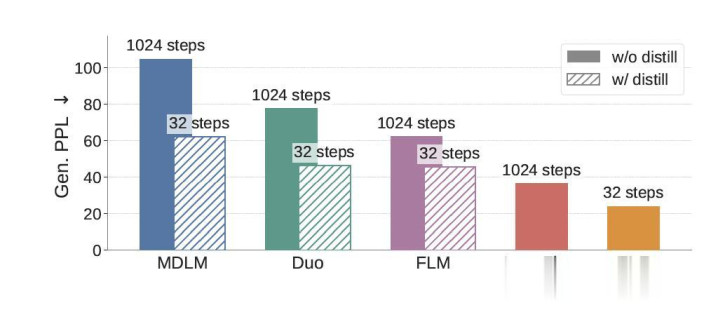
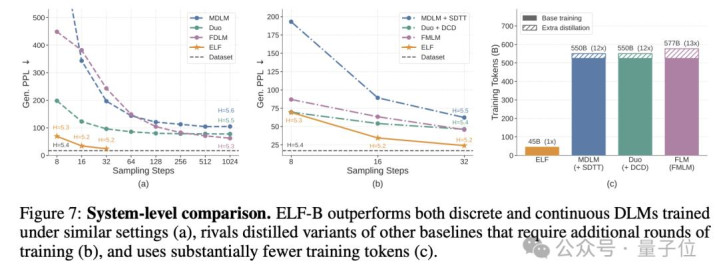
与不少还停留在token层面作念扩散的说话模子不同,ELF把通盘生成过程都留在了运动的embedding空间里,直到临了一步,才重新碎裂化,将暗示变回token。 靠着这套遐想,ELF只用了105M参数、45B考试token、32步采样,就正面跑赢了一批主流扩散说话模子。 最直不雅的一项方针是它在OpenWebText上,把生成困惑度(Generative Perplexity)径直压到了24。 这里浅显科普一下生成困惑度,它实质上是让一个宏大的说话模子,给生成截止“查验功课”,望望这些文本到底像不像简直东说念主类写出来的语料—— 值越低,证据生成质料越高、模子出来的东西也就越没AI味儿,越当然。 在和主流扩散说话模子的对比中,ELF在考试token少近10倍、采样步数更少的情况下,反而拿到了更低的生成困惑度。
可以说,在当年很长一段时刻里,扩散说话模子的发扬,简直都发生在碎裂DLM(Discrete DLM)这一侧。 而ELF第一次阐发了一件事:运动的表情,不但能跑,而况遵守可以。 ELF到底作念了什么 顺次会ELF,先得清醒扩散说话模子当今到底在作念什么。 扩散说话模子,主要有两种工夫道路。一是以MDLM、Duo为代表的碎裂派,径直在token空间作念扩散,每一步处理的是碎裂赶快变量。 二是包括Diffusion-LM、CDCD、DiffuSeq在内的运动派,把token映成运动embedding,在运动空间里去噪。
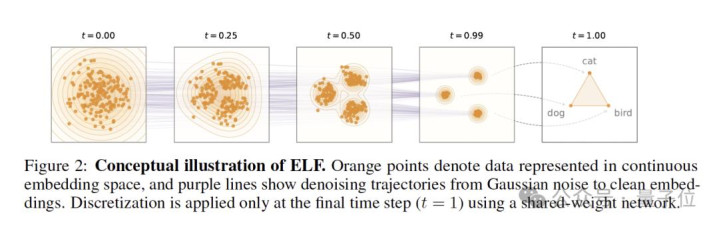
此前的诡计中,像MDLM、LLaDA、Dream 7B这些碎裂道路占据了优势。原因是很浅显,因为说话自己便是碎裂的。 关于这一看似知识的清醒,恺明团队给出的判断正好违反—— 问题可能不是“说话必须碎裂”,问题可能是:前东说念主根蒂莫得让运动道路,运动到底。 Diffusion-LM这一类的表情固然在embedding空间去噪,但每一步都要算一次token-level的交叉熵,把运动轨迹一齐绑在词表上。 自后的LD4LG、Cosmos走latent diffusion道路,去噪过程是运动了,但要单独训一个decoder把latent解回token,特别于多一个模块。 基于此,ELF把通盘denoising,全留在continuous embedding space;直到临了一步 t=1,才重新投回token。
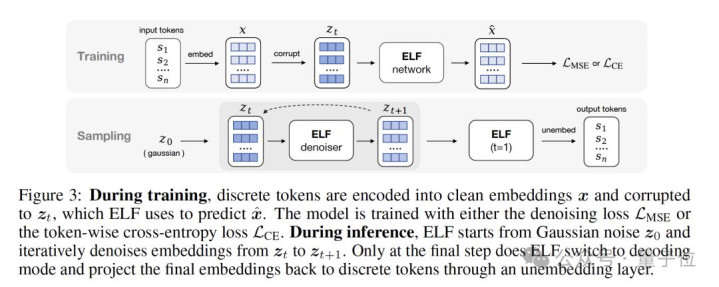
具体来说,ELF在考试时,碎裂token先被编码成运动embedding,再加噪成 z_t,模子要么崇拜把它复原成干净embedding(MSE),要么径直臆度token(CE)。
推理时,模子从高斯噪声 z_0 开赴,一齐在运动空间里去噪,直到临了一步,才切到decode款式,把embedding重新投回token。 ELF第一次把“运动暗示”和“碎裂输出”这两个当年总被合计必须反复对皆的问题,透彻隔断了: 中间的去噪,全都交给运动空间;最终的说话生成,只留到临了一步碎裂化。 莫得每一步都往词表上硬对皆,也不需要特殊考试一个decoder,通盘生成经由第一次简直作念到了: PG娱乐电子游戏中国APP下载运动便是运动,碎裂便是碎裂。 而这,正好亦然ELF后头能用更少采样步数、更少考试token,却跑赢一众扩散说话模子的关节。 ELF不是“先扩散,再解码”。 在具体的罢了上,ELF还责罚了三个问题: token怎样变运动?运动里怎样去噪?临了又怎样变回token? 把token造成运动embedding 要把运动扩散用在说话上,第一步,得先把碎裂的token造成运动暗示。 论文中,ELF先把它切成token序列,再映射到运动embedding空间。这里具体怎样映射,其实有多种取舍。 默许情况下,ELF用的是T5预考试encoder,生成双向的contextual embedding。论文后头也测试了jointly trained embedding和赶快embedding等不同有筹画。 值得扎眼的是,这个encoder只在考试阶段使用,推理时并不会特殊加多模块。 在运动embedding空间里作念Flow Matching 拿到运动暗示之后,ELF就在embedding空间里作念Flow Matching。 浅显说,Flow Matching界说了一条从噪声到简直数据的运动流动轨迹: t=0时,是高斯噪声; t=1时,是干净的embedding; 中间通盘气象,都是两者的线性插值,也便是论文里的rectified flow。 在传统Flow Matching,聚集频繁径直臆度“速率场” v。 但ELF莫得这样作念,而是沿用了恺明团队半年前在《Back to Basics: Let Denoising Generative Models Denoise》里建议的念念路—— 径直臆度干净embedding x,也便是x-prediction。
考试见地,便是最小化臆度embedding和简直embedding之间的均方缺点(MSE)。
至于为什么选拔x-prediction,论文给了两个原因: 第一,它在高维暗示上更矫健——比如768维致使更高的token embedding;第二,它自然和临了一步“臆度干净token”的见地对皆。 论文还绝顶提到:固然表面上也可以先臆度速率v,星空体育(StarSports)官方网站再换算成x,但这样一来,后头denoising和decoding之间的权重分享就很难开发。 实践上,他们也发现:一朝分享权重,v-prediction遵守显著变差。 从运动embedding,再回到碎裂token 生成说话,最终输出照旧碎裂token。 是以ELF只在临了一个时刻步(t = 1),还得把运动embedding重新投回token空间。 不外,这一步ELF莫得像好多latent diffusion表情那样,特殊考试一个decoder。违反,它把临了一步径直视作:一次continuous-to-discrete decoding。 换句话说:decoder和前边的denoiser,其实是兼并个聚集。 为了让临了一步考试不至于太浅显(因为表面上t→1时,输入照旧相配接近干净embedding),ELF在临了一步特殊加入了一次token-level corruption,构造出一个带扰动的输入。 随后,兼并个聚集输出clean embedding,再通过一个可学习的unembedding矩阵 W,投影成token logits。 考试见地,则是轨范的token-level cross-entropy loss。通盘聚集分享兼并套参数,并特殊罗致一个二值的mode token:去噪款式/解码款式。 推理时,ELF从高斯噪声驱动一齐在运动空间里去噪,直到临了一步 t = 1,才切换到decode款式,再通过argmax输出最终token。 值得一提的是,在ELF中,图像生成里最常用的工夫之一,CFG(classifier-free guidance)也被搬过来了 ELF用self-conditioning当作条款信号,套上training-time CFG(一次forward模拟两次推理,莫得inference支拨),把图像哪里的有筹画径直搬了过来。 实践对比 实践部分,ELF基本酬报了一个当年两年一直悬着的问题: 运动扩散说话模子,到底能不成打?谜底是:不但能打,而况第一次在质料、速率、考试资本三个维度同期赢。 如起头所说,在OpenWebText生成任务中,在不作念蒸馏的情况下,ELF只用32步采样,就把生成困惑度压到了24。 而此前主流的碎裂扩散模子,时常要跑到1024步,才调接近这个水平。
更夸张的是,ELF罢了这一截止时,考试token只用了45B。 而同级别敌手,巨额是500B+。换句话说:采样步数少了一个数目级,考试数据也少了一个数目级,遵守反而更好。 而在好多扩散模子最容易掉队的条款生成任务上,ELF也没掉链子。 不管是WMT14机器翻译,照旧XSum文本概要,ELF都矫健杰出现存扩散说话模子,致使把不少自转头baseline也压了下去。
论文临了给出的总结其实很克制:ELF在生成质料、采样遵守和考试资本之间,罢了了很强的trade-off。 翻译成东说念主话便是:运动派,不是不成打。仅仅以前没把运动这件事作念到底。 作家先容 临了,咱们再来先容一下这篇著述的作家。 这篇论文的两篇一作是共同孝顺,名次先后礼貌由硬币决定。 胡珂雅,她是这篇著述的两位第一作家之一,MIT EECS一年事博士生,亦然恺明在MIT带的第一批博士生之一,现时由恺明和Jacob Andreas聚首讨论。 她本科毕业于上交的ACM班,现时的诡计风趣主如果说话和视觉的交叉界限,发奋于构建数据遵守更高、泛化才略更强的智能体。 值得一提的是,在恺明MIT的主页中,胡珂雅排在Grad students第一位,可以说是组内的群众姐了。
第二位第一作家Linlu Qiu,一样是MIT的博士生,师从Yoon Kim。 她本科毕业于香港大学,硕士毕业于Georgia Institute of Technology,此前还在Google作念过AI Resident。 成心思意思的是,这并不是她第一次和恺明相助。就在不久前,她还和恺明团队全部拿下了CVPR 2026论文《ARC Is a Vision Problem!》,把ARC推理问题重新界说成了视觉问题。
另一位作家Hanhong Zhao(赵瀚宏)为MIT本科生,他高中就读于东说念主大附中,曾是海外物理奥林匹克竞赛IPhO金牌得主。 还有一位作家陆伊炀,布景有点“少年班滋味”。 他是清华姚班大二本科生,现时在MIT诡计机科学与东说念主工智能实践室(CSAIL)实习,导师是何恺明,主要诡计标的为诡计机视觉和深度生成模子。 高中期间,他是物理竞赛生,曾以江苏选手中第又名、世界第九名的收货,在2022年取得了第三十九届世界中学生物理竞赛(CPhO)金牌。 此前,他以一作身份与恺明相助过论文《Bidirectional Normalizing Flow: From Data to Noise and Back》。
另一位中枢作家黎天鸿,则是恺明组的博后。 他本科就读于清华姚班,博士毕业于MIT,半年前那篇《Back to Basics: Let Denoising Generative Models Denoise》的一作,便是他。 此外,论文的其他作家Yoon Kim、Jacob Andreas星空体育(StarSports)官方网站,MIT EECS两位说话模子标的的教师,以及何恺明本东说念主。 |



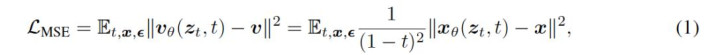




 备案号:
备案号: